
Need to sync S3 data between AWS Global and AWS China? Cross-region replication doesn’t work across the partition. This post walks through a serverless, event-driven architecture that solves it: no VPN, no persistent infrastructure, fully compliant.
If you’ve ever tried to move data between AWS Global and AWS China, you know it’s not just a matter of turning on replication. VPNs add complexity, and regulatory hurdles make everything feel fragile.
The Problem That Sparked the Idea
Imagine you have a product that stores user-uploaded files in AWS Global (say Virginia), but your operations team or customer base in China needs access to those files.
AWS Global and AWS China operate as separate partitions (aws vs aws-cn) with independent IAM systems, endpoints, and control planes. There’s no cross-partition S3 replication. No magic checkbox.
I needed something lightweight, scalable, and compliant. And preferably serverless.
The Spark: What If China Pulled the File?
Instead of replicating or pushing data directly into China (which could trigger compliance alarms), what if we inverted the flow?
What if the China side pulled the file?
All it would need is a valid presigned URL.
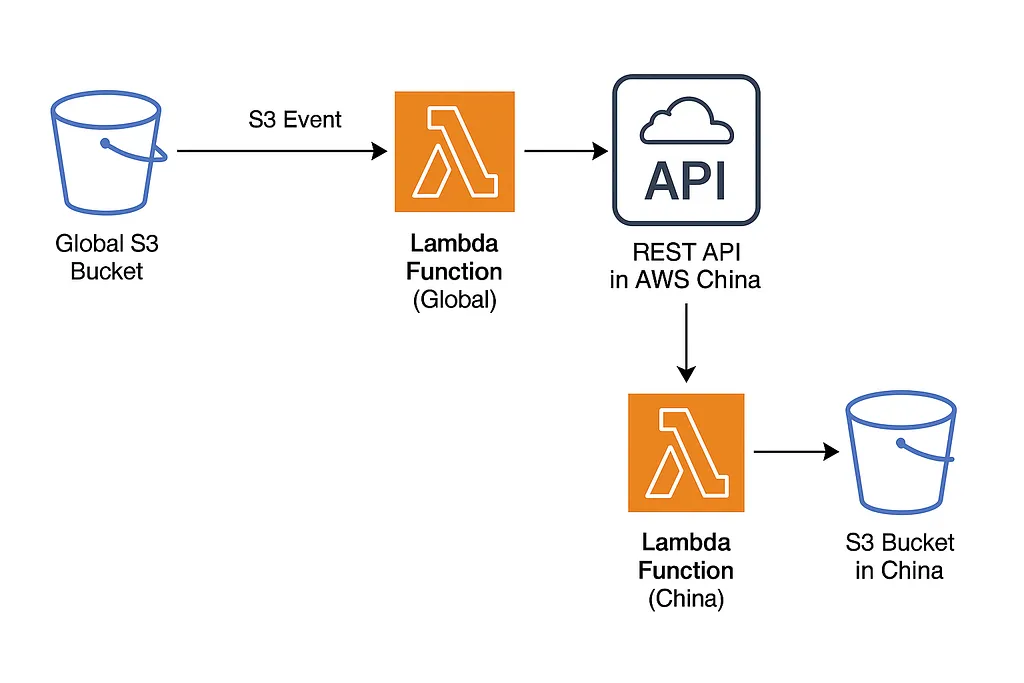
The Architecture That Emerged
Here’s the flow I built, and it’s simpler than you’d expect:
- A file lands in the S3 bucket (Global).
- That triggers a Lambda function, which generates a presigned URL.
- The Lambda POSTs this URL to an API endpoint in AWS China.
- The China-side API (API Gateway + Lambda) pulls the file using the URL and uploads it into an S3 bucket in the China region.
Why This Works Surprisingly Well
Operationally Simpler for Compliance: Data enters China through a controlled pull initiated inside the region, avoiding direct cross-border push.
No Credential Crossing: Global Lambda doesn’t need AWS China credentials (and vice versa).
Purely Serverless: No EC2, no databases, no persistent infrastructure. Just events and functions. For a deeper look at when serverless is the right call, see Serverless vs Containers: A Decision Framework.
Scalable by Design: Works for any number of files, assuming reasonable frequency and size.
Implementation in Brief
Global AWS Lambda (Triggered by S3)
- Enable S3 event notifications on object creation.
- Lambda creates a presigned URL and POSTs it to the China API endpoint.
AWS China Lambda (Receives URL & Uploads to S3)
- API Gateway receives the request.
- Lambda parses the presigned URL.
- Downloads the file using the presigned URL and uploads it to S3 China.
Tip: Use environment variables to keep API URLs and bucket names flexible and secure.
Lessons and Watch-outs
Presigned URL Expiry: China-side must download quickly after receiving the URL. Lambda’s execution role uses temporary credentials, so the presigned URL cannot outlive those credentials. The 7-day maximum you see in the docs only applies to IAM user long-term credentials.
If you need longer-lived presigned URLs, explicitly call sts:AssumeRole within your Lambda code with a DurationSeconds parameter (up to 12 hours). Note that the MaxSessionDuration role setting does not affect Lambda’s automatically-provided credentials.
API Security: Use API keys and rate limiting to protect the China endpoint.
Retries: Build retry logic in case downloads fail or take too long.
Cross-border network reliability: Traffic between AWS Global and AWS China passes through the Great Firewall, where bandwidth can be unpredictable. Lambda’s 15-minute execution timeout may not be enough for large files. Keep individual objects small, or consider S3 multipart upload on the China side so partial progress isn’t lost if a transfer is interrupted.
ICP filing requirement: If you use a custom domain for your API Gateway endpoint in AWS China, you will need an ICP filing. Unauthenticated, public-facing APIs require a full ICP License (not just a Recordal). Make sure your domain is registered before deploying the China-side endpoint.
Add a dead-letter queue: Without a DLQ or persistent tracking mechanism, failed transfers are silent. An SQS dead-letter queue on the China-side Lambda gives you visibility into failures and an easy path to retry.
Scope: This approach works well for low-to-moderate volume workloads and small-to-medium file sizes. When you outgrow it:
- Over ~100k objects/day: add SQS buffering to decouple ingestion from transfer
- Large files (500MB+): use an EC2 or containerized worker with resumable downloads
- Strict transfer SLAs: consider a Direct Connect link between partitions
Final Thoughts
Sometimes the best solution is the least flashy one. Here’s how this approach stacks up:
| Approach | Pros | Cons |
|---|---|---|
| VPN + EC2 | Full control over transfer | High operational overhead |
| Direct Connect | High bandwidth, low latency | Expensive, long lead time |
| Serverless pull model | Minimal infra, pay-per-use | Not suited for large files or strict SLAs |
This “push + pull” model won’t handle terabytes per hour, but it elegantly solves the problem of syncing S3 data across geopolitical and regulatory lines, without spinning up heavy infrastructure. And for workloads that fit, the cost profile is hard to beat.
If you’re dealing with similar constraints, this might just be the bridge you’re looking for.





Discussion
Comments are powered by GitHub Discussions. Sign in with GitHub to join the conversation.